
TFLite Simple regression 모델 생성
Updated:
TFLite에 대한 개발 workflow를 연습할 수 있는 GitHub repo my-tf-training에 대한 설명서이다.
GitHub repo my-tf-training 테스트 버전 정보
- OS : Ubuntu 18.04.4 LTS
- TF : tensorflow 2.2.0
1. 모델 생성
전체 workflow를 실습해볼 아주 간단한 TF 모델을 생성해보자. 본 가이드의 주 된 목표가 TF 모델을 TFLite로 변환하여 Edge Device에서 배포를 하는 과정을 살펴보는 것이기에 ML 모델에 대한 설명은 주요하게 다루지 않는다. repo에서 01-simple-regression.py에서 해당 모델 생성 코드를 볼 수 있다.
간단한 모델이긴 하지만 무슨 일을 하는지는 살펴보자. 아래처럼 numpy를 이용해서 100부터 차례로 정의된 테스트 사이즈(=100)만큼 array를 생성하여 _input으로 할당한다. _output은 _input에 100을 곱하고 5를 더했다. 간단한 함수 형태로 y=x*100+5라고 표현할 수 있다.
_input = np.arange(100, 100+test_dimsize)
_output = _input * 100 + 5
생성된 _input, _output을 원소를 보면 의도한 대로 잘 할당이 된 것을 알 수 있다.
_input : [100 101 102 103 104 105...
_output : [10005 10105 10205 10305 10405 10505...
모델 선언 부분이다.
model = keras.Sequential([
tf.keras.layers.Dense(10, input_shape=[1]),
tf.keras.layers.Dense(1)
])
model.compile(optimizer=keras.optimizers.Adam(0.01),
loss='mse')
keras의 Sequential class를 사용해서 Dense Layer를 2개 쌓았다. 첫번째 레이어는 unit 갯수가 10개이고, 두번째 레이어는 1개이다. 모델 생성 결과를 보기 위해서 Dense Layer를 의도적으로 2개 생성한 것이며, 본 모델을 통해서 해결하고자 하는 함수 y=x*100+5는 정확히 말하면 unit 1개 짜리 Dense Layer 1개만 있어도 가능하다. 머신 러닝에 대한 기반 지식이 있으면 바로 이해할 수 있는 내용이다.
model.summary()를 통해서 생성한 모델의 결과를 볼 수 있다.
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 10) 20
_________________________________________________________________
dense_1 (Dense) (None, 1) 11
=================================================================
Total params: 31
Trainable params: 31
Non-trainable params: 0
_________________________________________________________________
epochs 2000를 적용한 학습을 실행한다.
model.fit(_input, _output, epochs=2000, batch_size=10, verbose=1)
그리 오래 걸리지 않으니, 한번 실행해보자. 학습이 진행되면서 loss가 계속 감소하는 것을 볼 수 있다.
Epoch 1/2000
10/10 [==============================] - 0s 556us/step - loss: 234131920.0000
Epoch 2/2000
10/10 [==============================] - 0s 666us/step - loss: 231501536.0000
Epoch 3/2000
10/10 [==============================] - 0s 549us/step - loss: 228788352.0000
Epoch 4/2000
10/10 [==============================] - 0s 535us/step - loss: 225539312.0000
Epoch 5/2000
10/10 [==============================] - 0s 668us/step - loss: 221321568.0000
Epoch 6/2000
10/10 [==============================] - 0s 486us/step - loss: 215988896.0000
Epoch 7/2000
10/10 [==============================] - 0s 506us/step - loss: 209266816.0000
Epoch 8/2000
10/10 [==============================] - 0s 630us/step - loss: 200801664.0000
Epoch 9/2000
10/10 [==============================] - 0s 570us/step - loss: 191063024.0000
학습이 종료되면 모델이 완성되었다. 완성된 모델에 테스트 값을 넣고 output를 확인해보자. 추론은 predict 함수로 실행한다.
test_output = model.predict(test_input)
학습하고자 한 함수 _output = _input * 100 + 5에 거의 근접한 결과를 보여줬다.
prediction test
input : [1, 2, 3, 4, 5]
output: [[104.60508728027344], [204.60755920410156], [304.61004638671875], [404.612548828125], [504.61505126953125]]
학습이 완료되면, weight 값들을 잃어버리지 않게 모델을 저장해주어야 한다. 아래 코드로 모델을 저장하였다.
#1. save model as tensorflow saved_model
model.save('saved_model/my_model')
지정한 경로인 ‘saved_model/my_model’에 가면 pb 파일과 2개 폴더로 모델 정보를 저장한 것을 볼 수 있다.
my-tf-training/saved_model/my_model$ ls
assets saved_model.pb variables
간단한 모델을 생성하여 학습을 진행하고, 학습 결과를 Tensorflow 모델 포맷을 저장까지 완료하였다.
2. 저장한 모델 로드하여 사용하기
모델 학습을 완료 후, weight들을 보존하기 위해서 모델 파일을 저장하였다. 저장한 모델을 로드하여 추론을 실행하는 방법과 저장된 모델 파일에서 모델 정보를 확인할 수 있는 방법을 몇가지 살펴보겠다. 02-load-and-plot-model.py 파일에 여기에 기술된 코드가 작성되어 있다.
2.1. 저장한 모델 로드하기
먼저 모델을 저장해둔 경로를 지정하여 모델 로드를 진행한다.
saved_path = 'saved_model/my_model'
print("loaded TF model %s" % saved_path)
loaded = tf.keras.models.load_model(saved_path)
이렇게 로드를 수행한 모델은 이제 01-simple-regression.py파일에서 수행한 것과 동일하게 predict를 수행할 있다.
test_output = loaded.predict(test_input)
모델을 저장할 때와 동일한 추론 결과값을 보여준다. 동일한 weight 값들을 사용했기 때문에 동일 결과가 나온다.
prediction test
input : [1, 2, 3, 4, 5]
output: [[104.60508728027344], [204.60755920410156], [304.61004638671875], [404.612548828125], [504.61505126953125]]
2.2. 로드한 모델 weight 보기
get_weights함수를 사용해서 로드한 모델의 wieght 값들을 직접 확인할 수 도 있다.
weight = loaded.get_weights()
Dense Layer의 kernel weight와 bias weight가 순서대로 출력된다.
weight len : 4
weight[0]
[[-3.3600955 -3.4743512 3.2170527 -2.0247366 -3.4912143 3.1692097
3.3408363 -3.430736 2.9086719 -3.1360543]]
weight[1]
[-0.4174036 -0.41901428 0.43737584 2.3624077 -0.40474245 0.4138354
0.40165183 0.6943627 0.40202582 -0.42355007]
weight[2]
[[-3.2607582]
[-3.0364933]
[ 3.467686 ]
[-2.238742 ]
[-3.099907 ]
[ 3.3282106]
[ 3.1494195]
[-2.740242 ]
[ 3.640357 ]
[-3.4839993]]
weight[3]
[0.80793583]
2.3. 로드한 모델 그래프로 저장
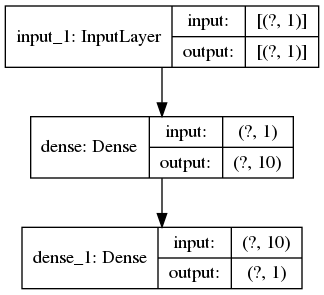
모델를 그래프로 그려주는 함수를 사용하면, 간략히 모델 그래프를 볼 수 있다.
tf.keras.utils.plot_model(
loaded, to_file='saved_model/my_model.png', show_shapes=True, show_layer_names=True,
rankdir='TB', expand_nested=False, dpi=96
)
아래와같은 png 파일을 생성하여 준다.
2.4. 로드한 모델 json으로 저장
모델 정보를 json 포맷으로 저장할 수 도 있다.
json_string = loaded.to_json()
with open('saved_model/my_model.json', 'w') as json_file:
pprint.pprint(json.loads(json_string), json_file)
저장된 json 파일에 아래처럼 모델 정보를 기술해주고 있다.
{'backend': 'tensorflow',
'class_name': 'Sequential',
'config': {'build_input_shape': [None, 1],
'layers': [{'class_name': 'Dense',
'config': {'activation': 'linear',
'activity_regularizer': None,
'batch_input_shape': [None, 1],
'bias_constraint': None,
'bias_initializer': {'class_name': 'Zeros',
'config': {}},
'bias_regularizer': None,
'dtype': 'float32',
'kernel_constraint': None,
'kernel_initializer': {'class_name': 'GlorotUniform',
'config': {'seed': None}},
'kernel_regularizer': None,
'name': 'dense',
'trainable': True,
'units': 10,
'use_bias': True}},
{'class_name': 'Dense',
'config': {'activation': 'linear',
'activity_regularizer': None,
'bias_constraint': None,
'bias_initializer': {'class_name': 'Zeros',
'config': {}},
'bias_regularizer': None,
'dtype': 'float32',
'kernel_constraint': None,
'kernel_initializer': {'class_name': 'GlorotUniform',
'config': {'seed': None}},
'kernel_regularizer': None,
'name': 'dense_1',
'trainable': True,
'units': 1,
'use_bias': True}}],
'name': 'sequential'},
'keras_version': '2.3.0-tf'}
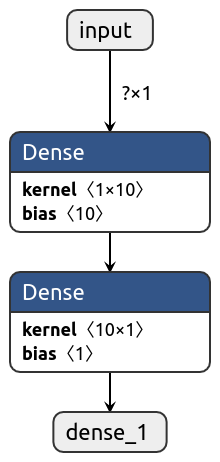
2.5. netron 어플로 모델 정보 보기
TensorFlow 코드는 아니지만, 모델 정보를 분석하는 유용한 어플인 netron이 있다. netron은 ONNX, Keras, Caffe 등의 여러 파일 포맷을 지원해준다. 모델의 그래프를 살펴보고 weight 값들 상세하게 볼 수 있어서 유용한 툴이다.
지금은 TensorFlow v2.2 모델 포맷에 오류가 있어서 모델 파일이 제대로 보이지 않는다. 01-simple-regression.py 파일에서 모델 파일을 Keras H5 포맷으로도 저장했는 것을 기억하자. 아래처럼 h5을 지정하면, 모델 그래프를 볼 수 있는 웹 주소를 알려준다.
my-tf-training$ netron saved_model/my_model.h5
아래처럼 그래프를 보기좋게 그려준다. 노드를 클릭하면 상세 정보를 볼 수 있다. 여기에서는 간략히 소개하지만 시각화에는 유용한 툴이니 한번쯤 설치해보길 권한다.

Leave a comment