
클리앙 모두의공원 게시글 분석기
Updated:
호기심에 시작한 클리앙 모두의공원 게시물 분석기이다. 분석을 시작하게 된 계기와 데이터 수집 & 가공 방법, 나름의 데이터 해석, 그리고 결론 순으로 기술하였다. 데이터 수집에 사용된 파이썬 웹 크롤러 스크립트와 데이터 가공에 사용한 파이썬 스크립트, 그리고 각 단계별 데이터들은 모두 GitHub repo에 공개하였다. 파이썬으로 웹 데이터를 모으는 방법과 데이터 가공 과정이 궁금하거나 커뮤니티 글들이 어떤 패턴으로 사람들 관심을 얻고 그 이후에 관심 밖으로 사라져가는지에 대한 호기심이 있다면, 이 글을 읽어볼만 할 것이다.
1. 도입 - 빅데이터를 모으고 분석해보자
근래 Python을 공부하게 되면서 업무에 여러가지 방법으로 사용할 수 있게 되었다. 데이터 해석이나 자동화에 Python script를 뚝딱뚝딱 만들어내어 일을 시키면 알아서 결론을 갖다바치는 모습이 매우 기특했다. (물론, 코딩 실력이 허접하여 일일이 수작업으로 처리하는게 스크립트를 짜는 것보다 빠른 경우가 비일비재하다.ㅠㅜ)
그러다 Python으로 좀 더 난이도 있는 작업이 하고 싶어졌다. 기왕이면 재미도 있었으면 좋겠다 싶었다. 그래서 생각해낸 것이 종종 가는 클리앙 모두의공원 게시글 분석이었다. 클리앙은 IT쪽 이야기가 많이 올라오는 커뮤니티로, 모두의공원은 자유게시판 이름이다.
이 곳에 글이 올라오면, 사람들이 얼마나 읽고, 얼마나 댓글을 달고, 얼마나 공감 버튼을 누르는지 살펴보기로 했다. 글이 처음 등록되고 1시간 단위로 얼마나 조회수/댓글수/공감수가 얼마나 발생했는지 기록하는 것이다. 단순히 생각하면 글이 등록되고 처음 1~2시간에는 많은 관심을 받을 것이다. 그리고, 시간이 지나갈수록 그 글은 새로 올라오는 글에 밀려 생명력을 잃고 사람들의 관심에서 멀어질 것이다. 또, 글이 등록되는 시간에 따라 그 형태가 달라질 것이다. 예를 들면, 점심시간에 등록된 글과 새벽에 등록된 글은 게시판 첫페이지에 머무는 시간이 다르기 때문에 이로 인한 차이가 분명히 존재할 것이다.
이 뻔한 스토리를 실제 데이터를 수집하고 분석해보면 게시글들이 실제로 어느 정도 생명력을 유지하는지 수치로 볼 수 있을 것 같았다. 또, 시간대 별 차이점을 살펴볼 수 있을 것이다. 그래서 일단 클리앙 모두의공원 게시판 정보를 수집하는 파이썬 웹 크롤러를 만들기 시작했다.
2. 데이터 수집 - 파이썬 웹 크롤러를 만들자
클리앙 모두의공원 게시판 정보를 수집하는 파이썬 웹 크롤러를 구상하기 시작했다. 파이썬 웹 크롤러가 잘 동작할 수 있을지, 클리앙을 이러저리 둘러보았다. 새 글을 등록되면, 클리앙에서 부여하는 id를 가지고 1시간 마다 해당 웹페이지를 다시 읽어서 조회수/댓글수/공감수를 저장할 수 있겠다고 생각이 들었다.
데이터 수집용, 파이썬 웹 크롤러 스크립트인 clien_buzz_rawdata.py를 작성하였다. Python은 version 3.5를 사용하였고 Python 패키지 중에 웹 크롤러로 많이 사용되는 BeautifulSoup를 주요 코드로 사용하였다.
파이썬 웹 크롤러 스크립트 clien_buzz_rawdata.py 의 동작을 간략히만 설명해본다. 스크립트는 동작을 시작하면 주기별로 모두의공원에 새 글이 등록되었나 확인한다. 이 확인 주기는 10분으로 하였다. 새 글 등록을 10분 주기로 확인한 이유는 새벽 시간대에 글이 많이 올라오지 않아서이다. 시간대별로 동일한 개수의 데이터를 수집하려고 하는데 새벽 시간대에 글이 많지 않으니, 오후 시간대에 많은 글을 수집할 이유가 없었다. 그래서 새벽 시간대에 글이 등록되는 수에 대략 맞춰서 10분으로 선정했다.
새 글이 등록되었다고 확인되면 python 내에 thread를 생성해서 이 글을 24시간 동안 추적하도록 임무를 할당한다. 이 python thread는 그럼 1시간 단위로 자기가 맡은 게시글의 조회수/댓글수/공감수를 조회하고 저장한다. 아래는 clien_buzz_rawdata.py 파일 내에 웹페이지를 읽어서 게시물의 제목, 공감수, 조회수 등을 확인하는 코드 부분이다.
...
bsObj = getBsObj(targetUrl)
bsObj = bsObj.find('div', attrs={'class' : 'content_view'})
post_title = bsObj.find('h3', attrs={'class' : 'post_subject'}).get_text()
post_title= post_title.replace('\n', ' ').replace('\r', '')
post_symph = bsObj.find('div', attrs={'class' : 'post_symph view_symph'})
if post_symph is None:
post_symph = 0
else:
post_symph = bsObj.find('div', attrs={'class' : 'post_symph view_symph'}).get_text()
post_symph = (int)(post_symph.replace('\n', ' ').replace('\r', ''))
post_view = bsObj.find('div', attrs={'class' : 'view_info'}).get_text()
post_view = (int)(post_view.replace('\n', ' ').replace('\r', '').replace(',', ''))
...데이터 저장에는 python pandas 패키지를 사용하여 csv 파일 형태로 저장하였다. csv 파일은 텍스트 포맷으로 데이터를 저장하기 때문에 간편하고 호환성이 좋아서 빅데이터 저장에 자주 사용된다.
3. 데이터 수집 결과
clien_buzz_rawdata.py 스크립트를 작성을 완료하고, 데이터 수집을 시작하였다. 스크립트 실행은 집에서 놀고 있던, 라즈베리파이에서 구동하였다. 데스크탑을 켜놓는 것보다 라즈베리파이에서 실행하는게 전기를 적게 사용해서 유리할 것으로 보았다. 데이터 수집은 19년1월23일 23시부터 2월1일 06시까지 진행되었다. 글이 등록되는 시간대별로 총 50개의 데이터를 수집하였다. 즉, 새벽 01시 대에 등록된 글을 50개를 수집하고, 오후 14시에 등록된 글도 50개씩 수집한 것이다.
데이터 수집에 약 7일이상 소요된 이유는 새벽시간에 글이 적게 올라와서이다. 시간대 별 동일한 글 갯수를 맞추려고 하다보니 오래 기다리는 것 밖에는 방법이 없었다. 그리고, 빅데이터를 표방하기에 많은 수를 데이터를 수집하고 싶었으나 시간 상의 한계가 보였다. 그래서 스몰데이터(?)인 시간대별로 50개씩 수집하기로 스스로 타협하였다. 그리하여 약 7일간 수집된 데이터 중에 시간대별 50개씩, 총 24시간이므로 50*24=1200개의 데이터 세트를 확정하였다. 1개 데이터 세트는 1개의 게시물에 대해 24시간 추적한 결과를 의미한다.
데이터 수집에 사용된 파이썬 웹 크롤러 스크립트인 clien_buzz_rawdata.py와 rawdata 결과물은 GitHub repo 의 01_rawdata 폴더 에서 모두 확인할 수 있다. 수집된 데이터는 게시물 id를 파일명에 기재하여 구분하였다. 데이터 파일 포맷인 csv의 데이터 열에 조회수, 댓글수, 공감수는 각 post_view, post_reply, post_symph로 표기하여 기재하였다.
아래는 게시물 id 13087379에 대한 결과 파일(csv)를 앞부분만 추출한 예시이다.
,check_time,id,post_reply,post_symph,post_time,post_title,post_view
0,2019-01-24 01:02:24.824668,13087379,3,0,2019-01-24 00:02:19, (종료) PS4 널널하네요 ㅎㅎ 무이자 12개월! ,1326
1,2019-01-24 02:02:30.142165,13087379,3,0,2019-01-24 00:02:19, (종료) PS4 널널하네요 ㅎㅎ 무이자 12개월! ,1400
2,2019-01-24 03:02:22.309552,13087379,3,0,2019-01-24 00:02:19, (종료) PS4 널널하네요 ㅎㅎ 무이자 12개월! ,1425
3,2019-01-24 04:02:27.411341,13087379,3,0,2019-01-24 00:02:19, (종료) PS4 널널하네요 ㅎㅎ 무이자 12개월! ,1442
4,2019-01-24 05:02:19.479744,13087379,3,0,2019-01-24 00:02:19, (종료) PS4 널널하네요 ㅎㅎ 무이자 12개월! ,1455
5,2019-01-24 06:02:24.620202,13087379,3,0,2019-01-24 00:02:19, (종료) PS4 널널하네요 ㅎㅎ 무이자 12개월! ,1475
...4. 수집 데이터 가공 & 시각화
이제 수집된 raw data를 기반으로 가공 및 시각화를 할 차례이다. 저장된 데이터를 어떤 방식으로 보여줄지 고민을 한 후, raw data를 시간대 별로 delta 값과 동일 데이터 군의 데이터 병합을 진행하기로 결정하였다. 데이터 가공 후에는 보여주고자 한 그래프를 python library를 사용해서 그래프로 그렸다. 각 스텝 별로 진행 내용을 간략히 표기하였으니, 자세한 부분은 같이 표기된 스크립트와 데이터 결과를 보고 판단하면 되겠다.
4.1. 게시물의 시간대 별 delta data 생성
01_rawdata 폴더에 존재하는 csv 파일들은 조회수/공감수/댓글수가 누적된 형태이다. 이를 앞 시간 대 데이터와 뒤 시간 데이터를 비교하여 delta 값(diff)을 생성하였다.
- 가공 : clien_buzz_step01.py
- 결과 : 02_step1 폴더
4.2. 시간대 별 data의 총합 계산(병합)
게시물 생성 시간대를 기준으로 각 시간별로 수집한 데이터는 50개 라고 말하였다. 이 50개 데이터의 총합을 구해 3개 파일(조회수/공감수/댓글수로 구분해서 3개 파일 생성)로 저장하였다.
4.3. 전체 data 병합
이전 단계에서 게시물 생성 시간대 별로 구해진 총합 데이터를, 다시 병합하여 1개 파일로 하였다. 이 단계에서는 조회수/공감수/댓글수가 각 1개 파일로 모든 데이터가 병합 완료되었다.
- 가공 : clien_buzz_step03.py
- 결과 : 04_step3 폴더
4.4. 전체 data 시각화
이전 단계에서 생성된 게시물 생성 시간대 별 샘플 그룹의 조회수/공감수/댓글수 데이터를 사용해서 그래프로 그렸다. 그래프 생성에는 matplotlib 라이브러리를 사용하였다. 그래프 종류는 3d bar를 선택하였다.
4.5. 게시물 생성 시간대별 샘플 그룹 시각화
이 단계에서는 게시물 생성 시간대별 샘플 그룹에 대한 시각화를 하였다. 이전 단계에서 생성된 게시물 생성 시간대 별 샘플 그룹의 데이터를 한번에 보여주기 위해서 3d bar 그래프를 사용했고, 이번에는 샘플 그룹 별로 시간대 별 추이를 보이고, 게시물 별 데이터를 쌓아보여주는 stacked 2d bar 그래프를 사용했다. stacked 2d bar 그래프는 plotly 라이브러리를 사용했다.
4.6. 게시물 생성 시간대 별 총 합 데이터 그래프
마지막 단계로 게시물 생성 시간대별 조회수/댓글수/공감수 데이터의 총합을 시각화하였다. 각 샘플 그룹 별로 24시간 데이터를 모두 합하여 간단히 막대 그래프를 생성했다.
- 가공 : clien_buzz_step06_total.py
- 결과 : 07_step6_total 폴더
4.7. (참고) matplotlib vs plotly 사용 후기
파이썬 graph/chart 등 데이터 시각화를 위한 라이브러리로 matplotlib, plotly가 널리 사용된다. 둘은 데이터 시각화라는 같은 목적을 가지고 있지만, 사용성이나 결과물에 대해서는 차이점이 발생한다. 그리고, 둘다 오픈소스이지만, matplotlib은 오픈소스 프로젝트이고 plotly는 plotly라는 회사가 주로 개발/배포한다. 그래서인지 plotly가 생성하는 그래프가 좀 더 깔끔하고 이쁜 경향이 있다. 그리고, plotly는 html 페이지로 그래프를 생성해서 다이나믹한 모습을 보여준다. html 페이지에서 그래프 위로 마우스를 올리면 해당 데이터 값을 보여주는 등 인터랙티브 분석이 가능하다. plotly html 기능은 뒤에 나올 결과 그래프에서 확인해 볼 수 있다. matplotlib도 다이나믹한 그래프를 그려줄 수 있지만, matplotlib 프로그램에서만 가능하다. 따라서, 다이나믹한 그래프를 배포할때는 plotly가 유리하다.(plotly는 python 외에도 R, JavaScript, MATLAB도 지원한다.)
각 라이브러리가 그려주는 그래프가 더 궁금하면 gallery 페이지를 방문해보자.
5. 데이터 해석
아래는 4.4. 전체 data 시각화 단계에서 생성한 그래프이다. 생성된 게시물 생성 시간대 별 샘플 그룹의 조회수를 시간 추이에 따른 변화량을 표시하였다. (클릭하면 커짐)
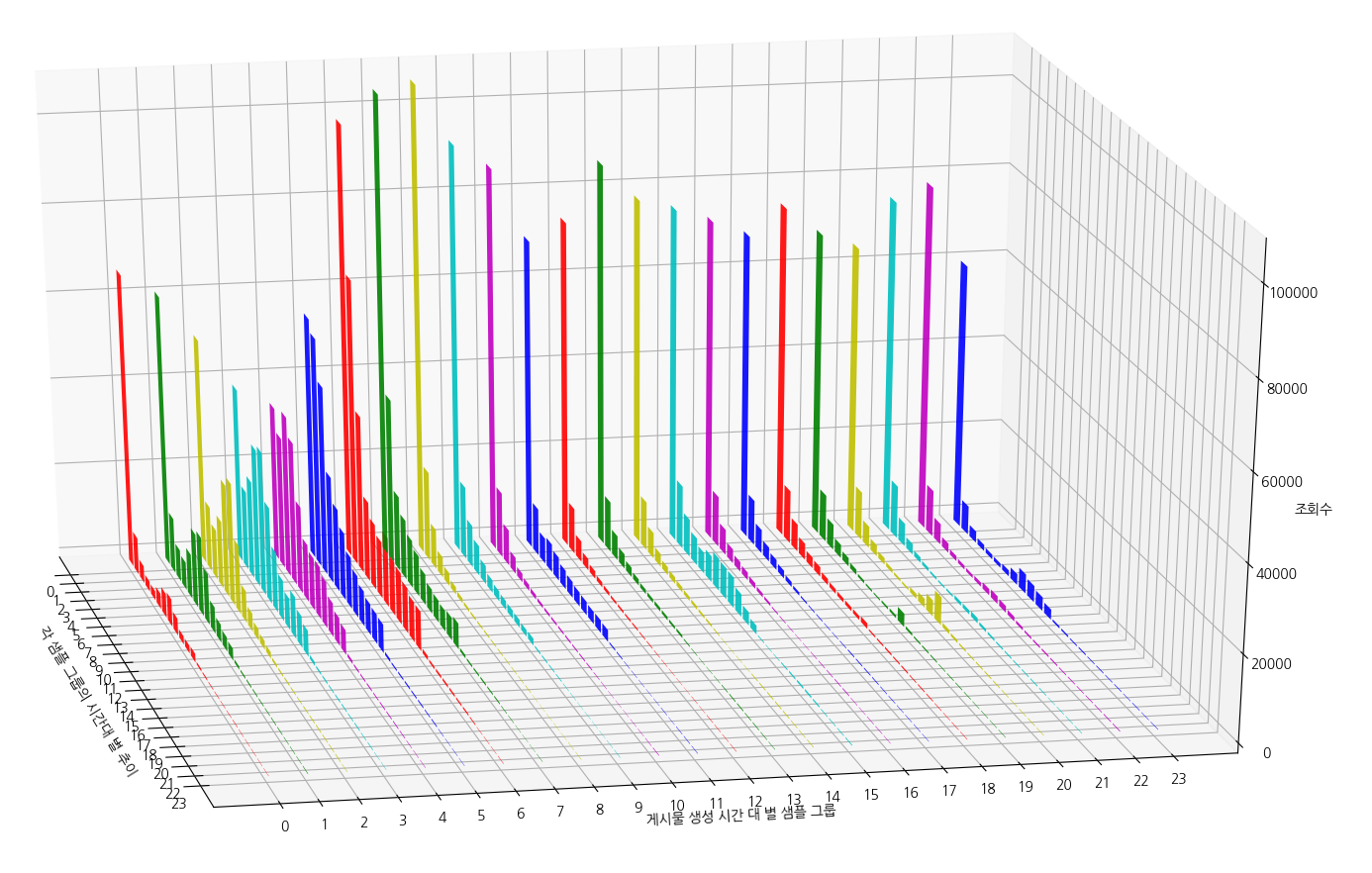
X축은 ‘게시물 생성 시간대 별 샘플 그룹’을 의미한다. Y축은 ‘각 샘플 그룹의 시간대 별 추이’를 의미한다. 예를 들어, X축 8의 그래프는 08시대에 생성된 게시물들(50개)의 조회수를 보여준다. X축 8의 그래프는 노란색이므로, 이 노란 그래프를 Y축으로 따라가보면 시간대 별 추이를 볼 수 있다.
08시 대에 생성된 게시물들의 조회수가 생성 후 24시간 동안 어떤 값을 갖는지 보여준다. 뻔한 이야기이지만, 생성 후 첫 1시간 동안은 많은 조회수를 보여준다. 시간이 지남에 따라 조회수는 급격히 하락하기 시작한다.
(주의) 수집된 각 시간대 별 게시물 수가 50개인 것을 잊지말자. 빅데이터라고 부르기 힘든 수이므로 이를 유의바란다. 그리고, 오늘의 추천글에 등록된 게시물은 아웃라이어(outlier)가 되어, 통계에 왜곡한다. 때문에, 통계적으로 신뢰도를 높게 잡지 말고, 추이만 봐야 할 듯 하다.
몇 개 시간대 그래프를 선택해서 살펴보도록 하자. 위 통합 그래프에서 시간대별로 게시물 데이터를 쌓아서 보여주는 stacked 2d bar 그래프 형태이다. 아래 그래프들이 plotly로 생성한 그래프이다. 클릭하면 위에서 소개했던 plotly html의 인터랙티브한 분석 기능을 살펴볼 수 있다.
5.1. 조회수 그래프 - 02시 생성 게시물
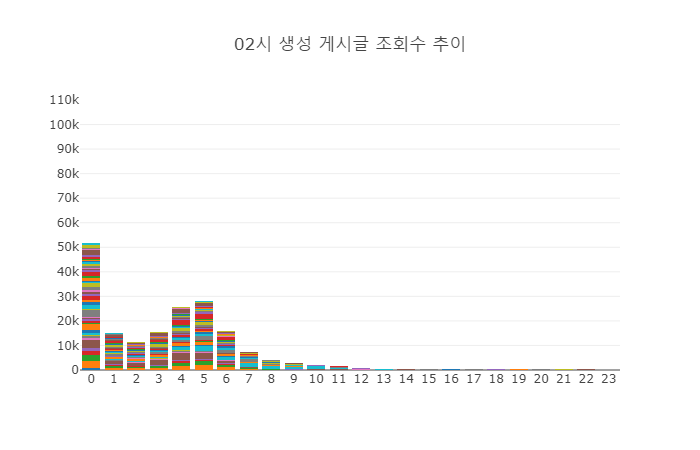
위 그래프는 02시 생성 게시물 50개에 조회수를 시간대 별로 쌓아서 보여주고 있다. 당연히 처음 1시간 동안의 조회수가 제일 많기는 하지만, 다른 시간대의 조회수에 비해서는 낮다. 이는 새벽 시간이기에 조회수가 떨어지는 것으로 보인다. 특이한 점은 글 생성 후 4~5시간 대에 조회수가 다시 상승한다는 점이다. 추측하기로는 02시 생성 게시물이 생성된지 4~5시간이 흘렀음을 의미하므로 6~8시 사이가 되고, 이 때 직장인들이 출근을 하면서 지난 글을 다시 읽는 것으로 보인다. 아침 시간 대에는 새로 생성되는 글이 많지 않으니, 간밤에 생성된 글들이 다시 조회되는 것으로 보인다. 새벽에 생성되는 글은 그래서 긴 생명력을 보여준다.
5.2. 조회수 그래프 - 08시 생성 게시물
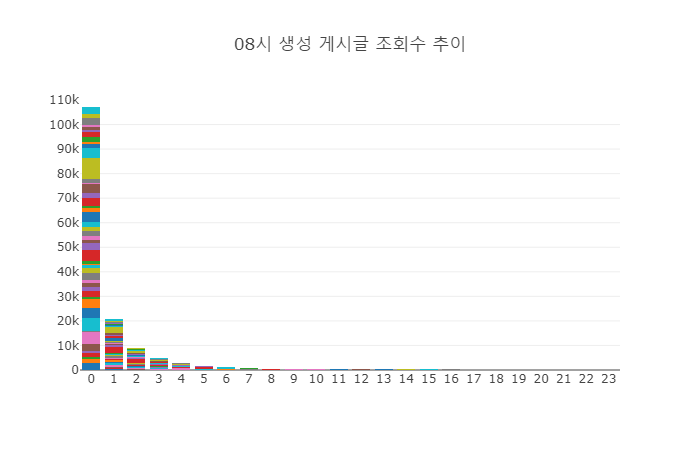
이번에는 08시 생성 게시물 50개에 조회수를 확인해보자. 08시 생성 게시물이 흥미로운 이유는 이 샘플 그룹이 첫 1시간 동안의 조회수 총합이 제일 높았기 때문인다. 추측하기에 아침 시간대라 상대적으로 적은 글이 올라옴에 따라서 조회수가 더 높아지는 결과를 가져오지 않았을까싶다. 시간의 흐름에 따라 조회수는 가파르게 하락한다. 새 글이 올라옴에 따라 게시물 순서가 밀려 조회수가 떨어지는 것으로 보인다.
5.3. 조회수 그래프 - 13시 생성 게시물
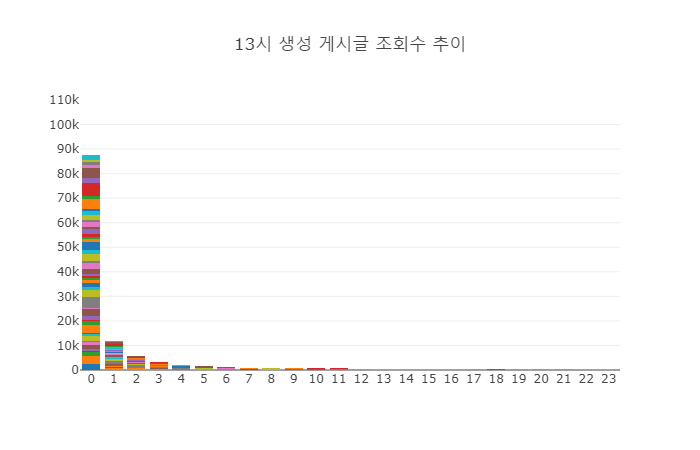
마지막으로 살펴볼 시간대 그래프는 13시 생성 게시물이다. 이 시간대는 오후 시간대의 조회수를 잘 대표한다. 첫 1시간 동안의 조회수는 많이 높고 그 뒤로는 급격히 하락한다. 하락의 속도는 오전 08시 생성 게시물 그래프 보다 급격하다. 이 때는 사람들이 글을 많이 보긴 하지만, 생성되는 글이 많기 때문에 관심 밖으로 밀려나는 속도가 매우 빠른 것으로 보인다.
5.4. 시간대 별 그룹 총 조회수 그래프
하나 더 그래프를 추가해본다. 시간대 별 샘플 그룹의 총 조회수를 그래프이다. 본 그래프를 보면 어느 시간대에 글을 게시하는 것이 상대적으로 많은 조회수를 얻을 수 있는지 통계적 힌트를 얻을 수 있다.
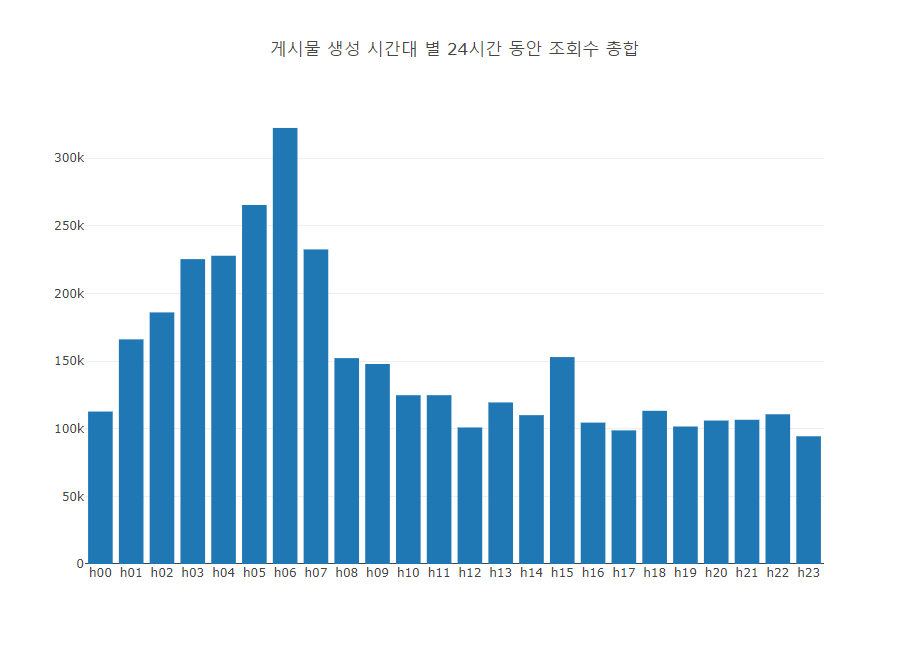
통계 결과를 보면 06시에 생성된 게시물들이 제일 많은 조회수를 갖는다. 새벽 시간 대에 올리는 글이 의외로 많은 조회수를 가지며, 오후~저녁 시간의 게시물들은 약간 낮은 조회수를 갖는다. 오후~저녁 시간의 게시물들이 의외로 낮은 조회수를 갖는 이유는 올라오는 글도 많아 뒤쪽 페이지로 빨리 밀려나기 때문인 것으로 보인다.
6. 전체 자료 공개
수집한 원본 데이터와 각 단계별 가공 데이터와 파이썬 스크립트는 모두는 GitHub repo에서 확인 할 수 있다. 또, 지면 관계 상 소개하지 못한 조회수/댓글수/공감수 그래프들은 Appendix 페이지에서 모두 볼 수 있도록 했다.
7. 결론
클리앙 모두의공원 게시글의 조회수/댓글수/공감수에 대한 빅데이터…가 아닌 스몰데이터를 수집하고, 게시글의 등록 시간대 별 조회수를 분석하고 내린 3줄 결론이다.
- 새벽 시간에 등록되는 글은 초반 조회수는 낮지만, 생명력이 길다.
- 오후 시간에 등록되는 글은 초반 조회수는 높지만, 생명력이 짧다. 상대적으로 금방 잊혀진다.
- 본인 글이 높은 조회수를 기록하기를 원한다면, 6시에 글을 등록하자.

Leave a comment